







Table of Contents
Recommendation engines use machine learning to suggest personalized content. It explores various recommendation algorithms and their operational mechanics, alongside elucidating the data-driven learning process of machine learning algorithms. Here, we aim to dissect the symbiotic relationship between machine learning and personalized recommendation engines, offering insights into their technical frameworks and potential advancements.
A Simple Definition of Recommendation Engines
Recommendation engines are algorithms designed to analyze user data and preferences to offer personalized suggestions. These systems operate across various platforms, including e-commerce websites, streaming services, and social media platforms. By examining user behavior, such as past purchases, views, and interactions, recommendation engines predict items or content that users might find relevant or interesting.
Using machine learning solutions, techniques, recommendation engines continuously refine their suggestions based on user feedback and interactions. In essence, recommendation engines serve as virtual assistants, helping users discover new products, movies, music, or content tailored to their individual tastes and preferences, enhancing overall user experience and engagement.
Importance of Personalization in Recommendation Engines
A personalized approach fosters a sense of connection and satisfaction, empowering users to explore new avenues and engage more deeply with the platform’s offerings. The other benefits it brings along for your avenue are:
- Enhances user experience by offering tailored suggestions.
- Increases user engagement and retention.
- Boosts conversion rates and sales for businesses.
- Facilitates discovery of new and relevant content.
- Fosters customer loyalty and satisfaction.
- Improves the effectiveness of marketing efforts.
- It helps filter out irrelevant information, saving time for users.
- Enables a better understanding of user preferences and behaviors.
- Allows for targeted advertising and promotions.
- Drives revenue growth through personalized recommendations.

How Machine Learning Algorithms Learn from Data?
Machine learning algorithms play a central role in recommendation engines by analyzing vast amounts of user data to generate personalized recommendations. Let’s explore how these algorithms learn from data:
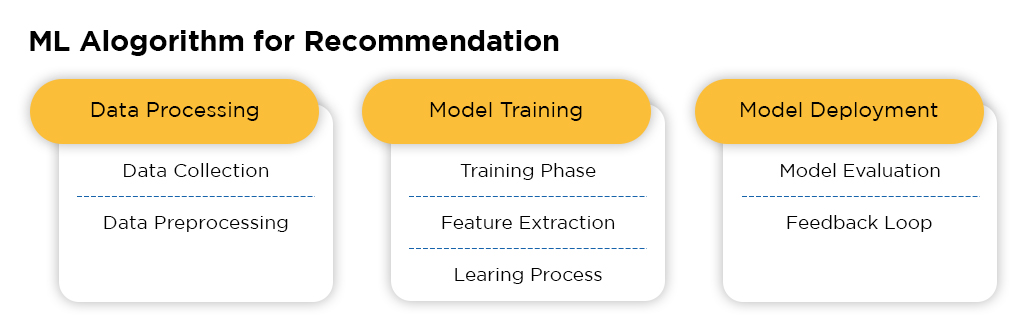
- Data Collection: Recommendation engines gather data on user interactions, preferences, and behaviors from diverse sources such as user profiles, browsing history, transaction logs, and explicit feedback mechanisms. This raw data forms the foundation for building personalized recommendation systems.
- Data Preprocessing: Before inputting data into machine learning algorithms, preprocessing steps are crucial to ensure data quality and compatibility. Techniques such as data cleaning involve handling missing values, removing outliers, and resolving inconsistencies. Normalization techniques standardize numerical features, while feature extraction methods identify relevant attributes from raw data to enhance model performance.
- Training Phase: During the training phase, machine learning algorithms ingest historical user-item interaction data to identify patterns and relationships. This phase involves optimizing model parameters through iterative processes such as gradient descent. Algorithms like collaborative filtering and matrix factorization analyze user-item interactions to generate recommendations tailored to individual preferences.
- Feature Extraction: Feature extraction involves transforming raw data into a format suitable for modeling. User-centric features may include demographics, past purchase history, or implicit feedback signals. Item attributes such as genre, category, or popularity are also important for understanding user preferences and building effective recommendation models.
- Learning Process: Machine learning algorithms employ diverse techniques like collaborative filtering, matrix factorization, or deep learning to learn from data and make predictions about user preferences. Collaborative filtering methods leverage user-item interactions to infer latent preferences, while matrix factorization techniques decompose the user-item interaction matrix to capture underlying patterns.
- Model Evaluation: Once trained, recommendation models undergo rigorous evaluation to gauge their effectiveness in generating relevant recommendations. Metrics such as accuracy, precision, recall, and F1-score quantify the model’s performance against ground truth data. Cross-validation techniques assess model generalization and robustness across diverse user scenarios.
- Feedback Loop: Recommendation engines maintain a continuous feedback loop by gathering user feedback based on interactions with recommended items. This feedback, whether implicit (click-through rates) or explicit (ratings, reviews), informs model updates and refinements. Techniques like reinforcement learning adaptively adjust recommendation strategies based on real-time user responses, ensuring dynamic and personalized user experiences.
By meticulously addressing each stage of the recommendation process, from data collection to feedback integration, recommendation engines can deliver highly personalized and relevant recommendations to users, enhancing overall user satisfaction and engagement.

Types of Recommendation Algorithms
Recommendation algorithms are the backbone of recommendation engines, determining how items or content are suggested to users based on their preferences and behaviors. Here’s a basic understanding of the types of recommendation algorithms:
| Algorithm Type | What It Does |
|---|---|
| Content-Based Filtering | Recommends items similar to those a user has liked or interacted with in the past. |
| Collaborative Filtering | Recommends items based on the preferences and behaviors of similar users or user groups. |
| Matrix Factorization | Decomposes the user-item interaction matrix to find latent factors representing user preferences. |
| Association Rule Mining | Discovers patterns and associations between items in transactional datasets to make recommendations. |
| Hybrid Recommender Systems | Combines multiple recommendation algorithms to provide more accurate and diverse recommendations. |
Understanding the various recommendation algorithms helps in building effective recommendation engines tailored to user needs and preferences.
Machine Learning Algorithms for Personalized Recommendation
1) Collaborative Filtering for Personalized Recommendation
Collaborative filtering remains a fundamental technique in personalized recommendation systems, offering flexibility, scalability, and effectiveness in generating relevant and personalized recommendations for users. By understanding the nuances and considerations of collaborative filtering methods, developers and data scientists can build robust and efficient recommendation engines that enhance user experience and engagement.
There are several approaches for collaborative filtering. Memory-Based Collaborative Filtering calculates similarities between users or items in the interaction matrix. User-based filtering compares preferences with similar users, while item-based filtering identifies akin items. Common metrics include cosine similarity and Pearson correlation. However, scalability may be an issue with large datasets. In contrast, Model-Based Collaborative Filtering learns latent factors from matrices using techniques like SVD and ALS. Optimization minimizes error functions like MSE, with regularization preventing overfitting. These methods are computationally efficient and scalable. Neighborhood-based Collaborative Filtering identifies similar users or items, offering interpretability and transparency in recommendations through techniques like KNN.
Advantages:
- Scalability
- Discovery of new content
- Dynamic adaptation
- Cold start mitigation
- Transparency
- Interpretability
- Cross-domain recommendations.
Challenges:
- Data sparsity
- Scalability issues
- Over-fitting
2) Content-Based Filtering for Personalized Recommendation:
Content-based filtering is a recommendation technique that focuses on analyzing the attributes or features of items to generate personalized recommendations. Unlike collaborative filtering, which relies on user interactions and preferences, content-based filtering leverages the intrinsic characteristics of items to make recommendations.
Content-based filtering begins by extracting relevant features or attributes from the items in the system. Once features are extracted, a user profile is created based on the user’s preferences and historical interactions with items. The user profile encapsulates the user’s preferences for different features and attributes of items. Content-based filtering matches the features of items against the user profile to determine relevance. Items with features that closely align with the user’s preferences are recommended to the user. The recommendation process involves calculating similarity scores between the user profile and each item in the system. Similarity measures such as cosine similarity or Euclidean distance are commonly used to quantify the similarity between feature vectors.
Advantages:
- Independence from user history
- Transparency
- Ability to recommend unique items
Challenges:
- Limited serendipity
- Over-specialization
- Cold start for new items
3) Matrix Factorization Techniques for Personalized Recommendation:
Matrix factorization is a widely used method in recommendation systems to glean latent representations of users and items from the interaction matrix. By breaking down the matrix into lower-dimensional counterparts, these techniques unveil patterns and relationships, fostering personalized recommendations.
The process involves representing the user-item interaction matrix as the product of two lower-dimensional matrices: the user matrix and the item matrix. Through optimization algorithms like gradient descent and stochastic gradient descent, the matrices iteratively adjust to minimize reconstruction errors. Regularization techniques like L2 regularization curb overfitting, fostering simpler and more generalized representations. Singular Value Decomposition (SVD) and Alternating Least Squares (ALS) are popular matrix factorization techniques employed to approximate the original matrix with a lower-dimensional representation. These techniques enable recommendation systems to generate personalized suggestions by capturing user preferences and item characteristics effectively.
Advantages:
- Personalization
- Scalability
- Flexibility
- Handle large data sets
- Accuracy
- Cold start mitigation
Challenges:
- Data sparsity
- Overfitting
- Cold start for new items
- Model complexity
4) Deep Learning Approaches for Personalized Recommendation
Deep learning approaches have transformed personalized recommendation systems by employing advanced neural network architectures to capture complex patterns and dependencies in user-item interactions. These methods excel at learning hierarchical representations of users and items from raw input data, such as user behavior sequences and item features.
By incorporating embedding layers to encode categorical variables and leveraging sequential modeling techniques like LSTM networks, deep learning models effectively capture temporal dynamics in user interactions over time. Attention mechanisms enable models to focus on relevant interactions, while neural collaborative filtering combines traditional techniques with neural networks to predict user preferences directly from data. Autoencoders and hybrid models further enhance recommendation accuracy by learning latent representations and integrating multiple data sources. Overall, deep learning approaches empower recommendation systems to deliver highly relevant and personalized recommendations to users.
Advantages:
- Complex Pattern Recognition
- Hierarchical Representations
- Temporal Dynamics Modeling
- Flexibility and Adaptability
Challenges:
- Data Scarcity
- Computational Complexity
- Overfitting
- Interpretability problems
- Cold Start problem
5) Hybrid Recommender Systems for Personalized Recommendation
Hybrid recommender systems combine multiple recommendation approaches to overcome the limitations of individual methods and provide more accurate and diverse personalized recommendations. It offers a balance between accuracy, diversity, and the ability to address various challenges associated with individual recommendation techniques.
The choice of a hybrid model depends on the specific goals, data characteristics, and requirements of the recommendation system.
Advantages
- Improved accuracy
- Diversity
- Cold start mitigation
- Serendipity
Challenges
- Complexity
- Data integration
- Scalability issues with large data
End Note
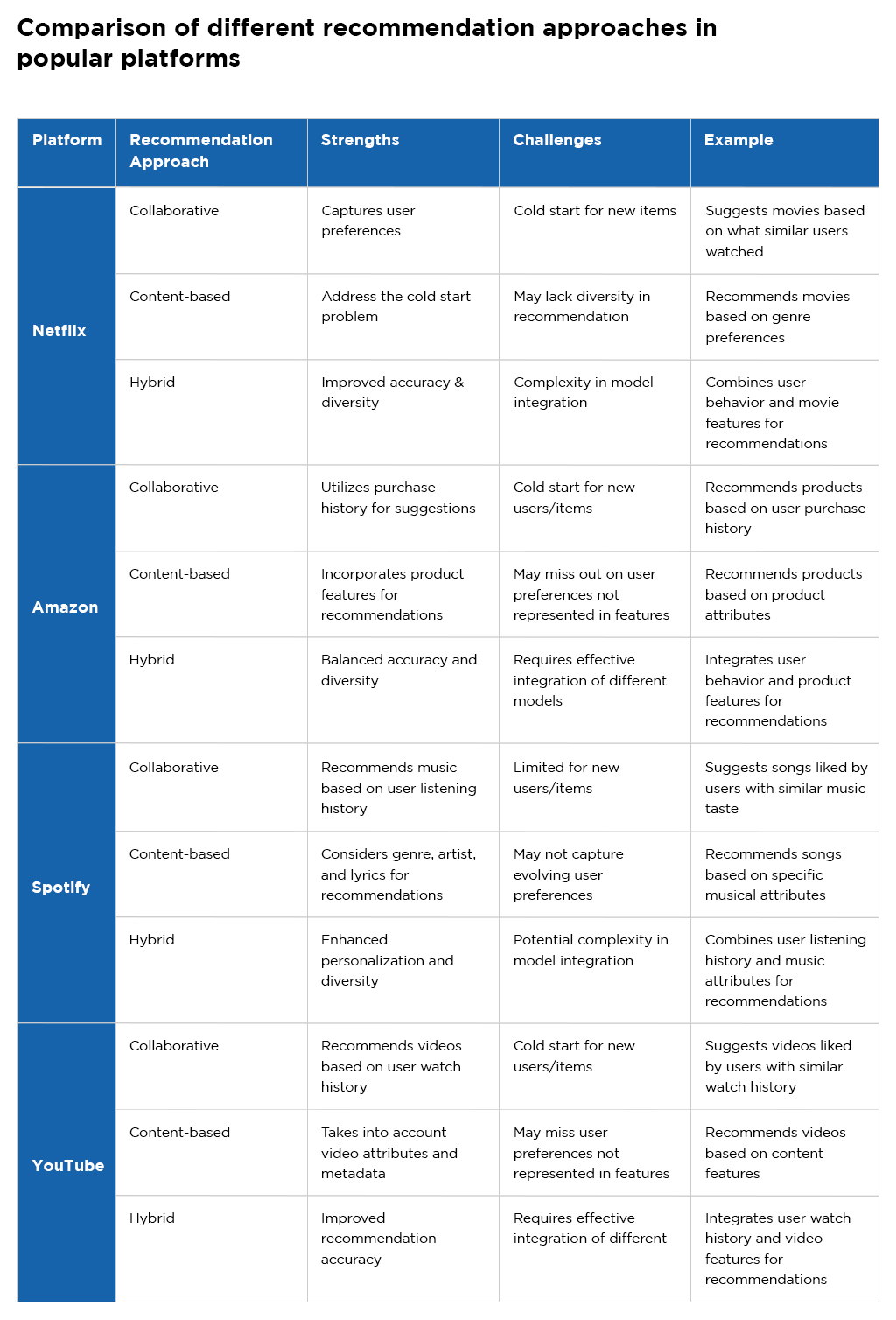
From Amazon’s precision in suggesting products to Netflix’s tailored movie selections, recommendation engines are the unseen architects of our digital journeys. Understanding these engines’ intricacies, whether collaborative, content-based, or hybrid, unveils the magic behind the recommendations that keep users engaged.
Elevate your user experience and unlock the potential for business success with our cutting-edge machine learning solutions. Ace Infoway offers tailored solutions to implement and optimize recommendation engines, ensuring businesses not only meet user expectations but exceed them. Explore the possibilities and turn recommendations into revenue!












